CRM Copilot
Automatisez l'exécution de la stratégie CRM à grande échelle

Orchestrez votre marketing client
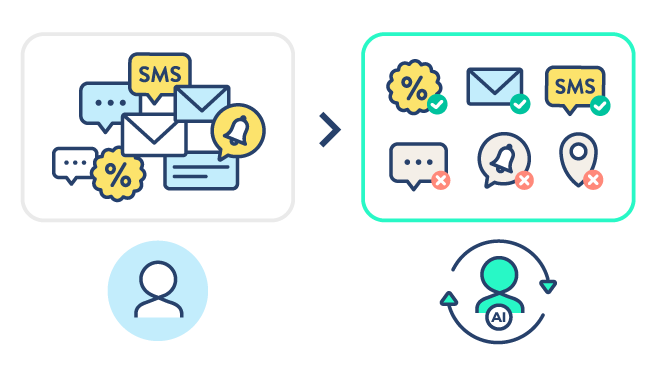
Intégrez la totalité de vos campagnes CRM et supprimez les silos entre vos campagnes ponctuelles et vos scenarios pour exploiter tout le potentiel de votre base client.
Chaque jour les meilleures opportunités de campagnes sont sélectionnées pour l’ensemble de vos clients tout en respectant vos contraintes de pression marketing.
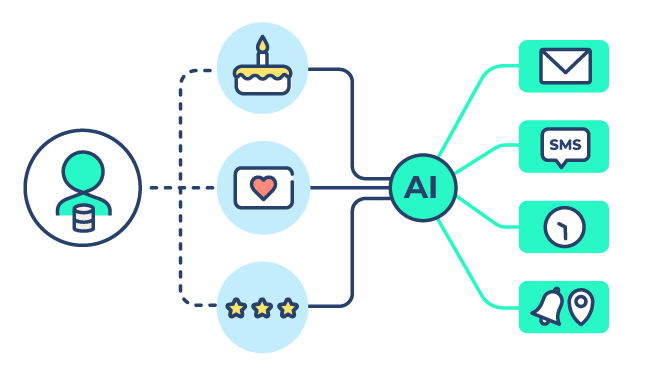
Bénéficiez de ciblages optimaux pour la totalité de vos prises de parole grâce à l’intelligence artificielle.